Architecture Updates - LLM Assistant for OpenROAD
Building a Conversational Assistant designed around OpenROAD
Hi again! I’m Palaniappan R, a GSoC contributor working on the OpenROAD chat assistant project under the mentorship of Indira Iyer and Jack Luar. My project aims to build an LLM-powered chat assistant designed to provide seamless access to existing online resources, thereby reducing support overhead. Over the past month, I’ve been collaborating with Aviral Kaintura, on data engineering to deliver on our common project goal of an OpenROAD assistant and an open-EDA dataset that promotes further research and collaboration.
Progress
The retrieval architecture is at the heart of any retrieval-augmented generation (RAG) setup. Our current setup employs a hybrid-search technique, combining a traditional keyword search method with more advanced vector search methods. As illustrated in the diagram, we combine a simple semantic search, a Maximal Marginal Relevance (MMR) search and a text-based BM25 ranking technique to build our hybrid retriever.
Upon receiving a query, relevant documents are sourced from each retriever, resulting in a broad set of results. We feed these results into a cross-encoder re-ranker model to get the top-n documents with maximum relevance.
After building the retriever, we utilized the LangGraph framework to develop a stateful, multi-agent workflow tailored to our use case. This allows flexibility in servicing a diverse set of user questions in an efficient and accurate manner, given the sparse nature of our dataset.
Our current dataset can be broadly classified into the following categories:
- OpenROAD Documentation
- OpenROAD-flow-scripts Documentation
- OpenSTA Documentation
- OpenROAD Manpages
These data sources are embedded into separate FAISS vector databases using open-source embeddings models (we’ve been working on fine-tuning an embeddings model for better retrieval accuracy). The hybrid search retrievers are then applied to these vector databases, creating internal tools that can be queried by our LLM as needed. Each tool has access to different data sources in various domains. For instance, the retrieve_cmds tool selectively has access to information detailing the multiple commands in the OpenROAD framework, while the retrieve_install deals with installation-related documentation. As depicted in the flowchart, a routing LLM call classifies the input query and forwards it to the appropriate retriever tool. Relevant documents are then sent back to the LLM for response generation.
Feel free to try out our chat assistant here. Instructions to set up and run our chatbot can be found here.
Here’s an example of our chatbot in action.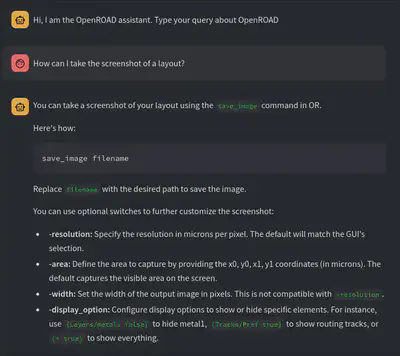
Future Plans
In the upcoming weeks, we aim to enhance our dataset by incorporating actionable information filtered from GitHub issues and discussions. We’ll be adding support to keep track of the conversation history as well.
Stay tuned for more updates!
Palaniappan R
Student at Birla Institute of Technology and Sciences, Pilani
Palaniappan R is an undergraduate student at BITS Pilani.